
One of the project of my team in former company was building a new system using event-sourcing pattern. Nobody is an expert in this topic and we were learning it along the way by trial and error. One design decision that turned out to be quite a big headache for us later is the dual writes on event store and message bus.
A bit background on Event Sourcing
Here is a super simplified example of it. A user data in normal system might looks like
UserAccount [ name: Jon Snow, Address: UpNorth, Interest: [Wolf, DeadManWalking]]
In event sourcing, the important results of system actions are captured as Event. The events are the things that get persisted on disk instead of the final state of information. The user information above may the final state of the events below.
UserCreatedEvent[name: Jon Snow, Address: Winterfell, entityId:1111, v:1] AdddressChangedEvent[Address: UpNorth, entityId:1111, v:2] InterestAddedEvent[Interest: Wolf, entityId:1111, v:3] InterestAddedEvent[Interest: DeadManWalking, entityId:1111, v:4]
The event list is append-only. Correction is done by appending new event to change the final state. We can see in the above example that address of the user has been updated to new one. This way, history of action is preserved for later uses such as replaying events to new logic or investigating old issues.
Another big benefit in using this pattern is to have multiple views, aka. projections , of the data. Same data could be parsed, indexed or stored in different way for different use cases. User account might be kept in rational database while Interests or subscriptions might be ingested to indexing system for search and ranking. Each consumer of the data is free to choose its own way and its own tech stack to handle data.
Dual writes in our implementation
We decided to use Kafka for publishing events to multiple projections. Message bus is a natural fit for pub-sub uses like this. Below is the high level diagram of the system.
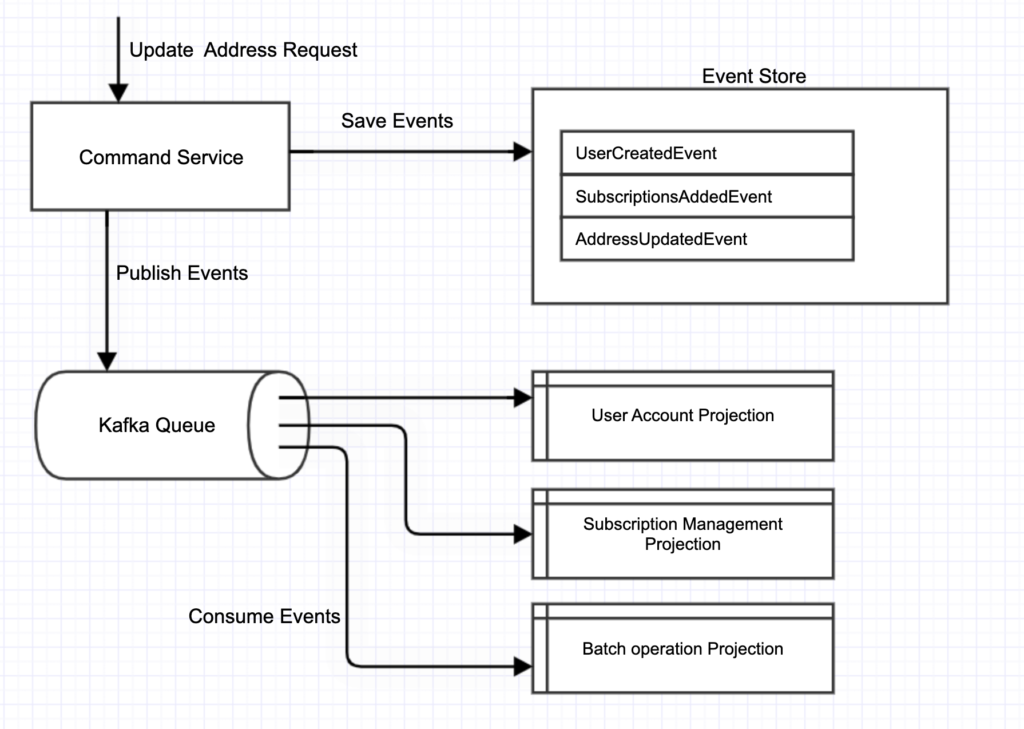
Execution flow
- Command Service proceed command requests (HTTP), compute the output state then save it to event store.
- After an event is commit to event-store, the service publish the event to projections via Kafka. That is the dual-writes I mentioned in the title. The same information get written to two different systems.
- Projections keep listening to new event and gradually update its state.
The event store is supposed to be single source of truth. But our use of message bus make it more complicated in keeping data consistence. Note that it will always be some inconsistency over some periods of time since each projection will process events in its won pace. Its just that using dual-writes make it more difficult in keeping projections in-sync with event store.
Imagine what should we do when an event is successfully saved to event store but fail in publishing to message bus. The business logic is done and event is persisted. That means the command is considered as successfully processed. But projections are relying on data in message bus so we just have to find someway to eventually get the failed events re-published to message bus.
Message Bus is normally design to have high availability you say? Yes I very well aware of that. A Kafka topic could have 1000 partitions distributed between many brokers. There are built in mechanism like partition leader moving to new node and write with minimum in-sync replicas that keep the system well running. But I myself was a Kafka admin. I can guarantee that there will always be outage time, all system have outage.
To handle this fail events publishing, we have to add quit a lot more to the system.
- Failed events will be saved to separate data store. We are using Google Spanner for this. The chance of our Kafka hosted internally in our company and Spanner instance hosted in Google Data center are having outage at the time should be extremely low.
- We create Replay Service to monitor failed events and try re-publishing events to message bus.
- Each projection will also detect events version skip. If the latest version of an event entity is 45 and the next consumed event is of version 50 then we know there are events missing. The projection must request to Replay Service to get events from the main source of truth; event store and re-publishing them again.
- Note that event processing in projection must be idempotent. Event version must be checked and ignore the events that are already processed. Note that this is not the effect of using dual-writes. Publishing messages through message bus is bound to have duplications (unless it is specifically configured with exactly-once delivery).
The system with this correction looks a lot more complicated.

What it should be
We invested too far with the dual-writes approach so we decided to not revised our architecture. But we did researching on how it should be implemented.
The event store should be the single source of truth. Each projection could pull events out of event store and process events at its own pace. Projection just need to keep track of (and persist) its current position in the event stream. The position will not advance next if the current event is fail in processing. The projection just have to keep retry or trigger alert to admin to investigate. The system will look a lot simpler.
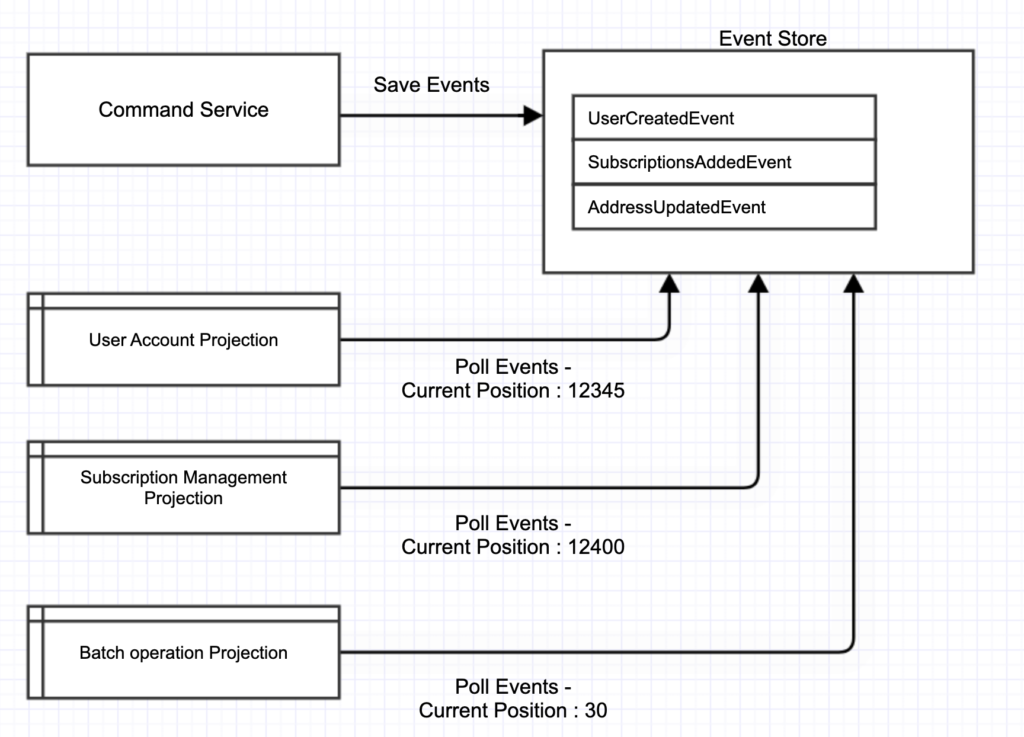
Note that there are some challenging of this pulling approach comparing with publishing through message bus. One concern is how to make event processing fast enough. Kafka comes with very useful data partitioning and consumer groups. We can easily adjust parallelism by increasing number of consumer. Partitions will be automatically distributed to all consumer in the group. It would be quite difficult to implement something like this in projection system.